Tämä on tarina siitä kuinka aloittamastani muutaman päivän projektista kasvoi kansallinen tietojärjestelmä ja epämuodollinen Suomi-Ruotsi -maaottelu, ja kuinka samalla puolihuomaamatta kehitin itselleni uuden työnkuvan. Juttu on pitkä ja alkaa taustoilla. Voit hypätä myös vuoteen 2009, jolloin järjestelmä sai alkunsa.
Tietokantojen monimuotoisuus
Yleisölle avoimet näyttelyt ovat näkyvin osa luonnontieteellisiä museoita, mutta suurin osa museoissa tehtävästä työstä liittyy tieteelliseen tutkimukseen. Museoissa tutkitaan mm. luonnon monimuotoisuutta, eliöiden sukulaisuussuhteita ja ympäristön muutoksia. Tutkimus perustuu tieteellisiin kokoelmiin, jotka ovat monta kertaluokkaa suuremmat kuin yleisön nähtävillä olevat kokoelmat.
Itse olen ollut erilaisissa tietotekniikkatöissä Suomen suurimmassa luonnontieteellisessä museossa – Luonnontieteellisessä keskusmuseossa Luomuksessa – jo toistakymmentä vuotta. Luomuksen varastoissa on noin 13 miljoonaa eliönäytettä, jotka on kerätty eri puolilta maailmaa muutaman viimeisen vuosisadan aikana: hyönteisiä, kasveja, loisia, jäkäliä jne. Näytteisiin liittyy myös tieto mistä ne ovat peräisin ja milloin ne on kerätty. Ilman näitä tietoja näytteillä ei olisi paljoakaan tieteellistä arvoa. Yhdessä luonnontieteellisten museoiden kokoelmat muodostavat valtavan tietovaraston maapallon luonnon monimuotoisuudesta ja sen kehityksestä.
Näytteitä on niin paljon, että kenelläkään ei ole tarkkaa käsitystä kokonaisuudesta. Vain pieni osa näytteistä on pystytty luetteloimaan jonkinlaiseen kortistoon – sähköiseen tai paperiseen. Perinteisesti näytteisiin liittyvä tieto on talletettu niihin kiinnitetyille paperilapuille eli etiketeille. Tällä tavalla talletettu tieto ei kuitenkaan ole helposti löydettävissä tai kokonaisuutena analysoitavissa, minkä takia suurin osa näytteistä ja niiden tiedoista on seisonut käyttämättöminä.

Vanhoja hyönteisnäytteitä Luomuksen kokoelmista. Valkoiset etiketit ovat myöhempien tutkijoiden kiinnittämiä määritysetikettejä. Oranssit ovat lainaetikettejä: nämä näytteet ovat olleet jollakin Luomuksen ulkopuolisella tutkijalla lainassa.
Ratkaisuna tiedon huonoon saavutettavuuteen on näytteitä ryhdytty digitoimaan, eli tallentamaan sähköiseen muotoon. Kehitys alkoi Luomuksessa 1960-luvulla, jolloin ensimmäisiä kasvinäytetietoja tallennettiin reikäkorteille. 1980-luvulla kasvinäytteiden tietoja ryhdyttiin siirtämään tietokantaan.
Kehitys on kuitenkin ollut epätasaista, ja 2000-luvulle tultaessa vain pieni osa Luomuksen näytetiedoista oli tietokannassa. Tällöin käynnistettiin ns. Luomus-hanke (josta Luomus sai myöhemmin nimensä), jossa oli tarkoituksena rakentaa tietojärjestelmä lajitiedon hallintaan (mm. museonäytteille sekä eliöiden nimille ja sukulaisuussuhteille). Hankkeessa tehtiin suuria suunnitelmia, mutta se lopulta lopetettiin kun rahoitusta ei löytynyt.
1990-luvulta alkaen Luomuksen osastoissa otettiin käyttöön erilaisia itsenäisesti tehtyjä Access-tietokantoja, Excel-tallennuspohjia ja tekstitiedostoihin perustuvia tallennusvälineitä. Kehitys riippui paljon yksittäisten työntekijöiden omasta aktiivisuudesta ja osaamisesta. Erään kartoituksen mukaan lajitietoa oli talletettu yli 80 erilaisessa muodossa. Useimmat näistä olivat vain muutaman työntekijän käytettävissä, eivätkä kaikki toimineet tyydyttävästi. Tietojen saavutettavuutta oli pakko ryhtyä parantamaan.
Ensimmäinen prototyyppi
Keväällä 2009 satuin juttelemaan museon yli-intendentti Jyrki Muonan kanssa. Hän ihasteli Costa Ricasta lainaksi saatua, viivakoodietiketillä varustettua näytettä: viivakoodin avulla näytteen tiedot sai helposti haettua nettiselaimeen katseltavaksi. Omassa mielessäni pyöri yksi asia: ”minäkin osaan tehdä tuon!” Ryhdyin luonnostelemaan miten uusi kokoelmatietojärjestemä voisi toimia, mutta lopulta asia kuitenkin jäi päätyöni jalkoihin – vastasin Luomuksen verkkosivuista ja olin mukana monenlaisissa pikkuprojekteissa. Eihän kokoelmien hallinta minulle kuulunut. Innostus jäi kuitenkin kytemään.
Joulun ja uudenvuoden välipäivinä 2009 päätin tarttua toimeen ja ohjelmoin muutamassa päivässä kokoelmatietojärjestelmän prototyypin, keneltäkään lupaa tai neuvoja kysymättä. Se sai nimen Hyntikka – hyvin yksinkertainen näytetietokanta. Hyntikka oli käytännössä Lean Startup -kirjassakin esitelty minimum viable product (MVP): yksinkertaisin mahdollinen mutta toimiva järjestelmä. Yksinkertaisuudessaan se oli varmasti oppikirjanvastainen, mutta täytti tarkoituksensa.
Prototyyppi-Hyntikka otettiin innostuneesti vastaan, ja vuoden 2010 aikana Luomuksen hyönteistiimit ryhtyivät tallentamaan siihen näytetietoja. Juttelin käyttäjien kanssa ja kehitin järjestelmää pikku hiljaa oman työn ohella. Vuoden 2010 lopussa tietokannassa oli 23.000 näytettä. Hyntikan käyttö kasvoi pikku hiljaa ja se alettiin kokea yhä tarpeellisemmaksi, myös koska vastaperustetusta digitointikeskus Digitariumista oli odotettavissa paljon uutta sähköistä näytetietoa säilytettäväksi.
Suomi-Ruotsi -maaottelun makua
Syksyllä 2010 Luomuksessa virisi uudelleen keskustelu Luomuksen (ja mahdollisesti koko Suomen) yhteisen kokoelmatietojärjestelmän käyttöönottamisesta. Samaan aikaan Ruotsissakin suunniteltiin kokoelmienhallintajärjestelmän rakentamista kansainvälisessä DINA-hankkeessa. Niinpä päädyimme vertailemaan vaihtoehtojamme: DINA:an liittyminen, kaupallisen Earthcape- tai avoimen Specify-järjestelmän käyttöönotto, tai oman järjestelmän kehittäminen Hyntikan oppien pohjalta.
DINA:an liittyminen houkutti, koska hankkeeseen oli mittava rahoitus sekä kova innostus, ja mukana oli myös Specify-kokoelmajärjestelmän kehittäjiä. Verrattuna ketterästi kehittyneeseen Hyntikkaan hanke vaikutti kuitenkin kankealta. Suunnittelu ja päätökset tehtäisiin kansainvälisissä työryhmissä. Uskoimme voivamme täyttämään vaatimusmäärittelyn suurelta osalta itse ja DINA:aa nopeammin. Päädyimmekin alkuvuonna 2011 jatkamaan omaa kehitystä.
Edessä oli siis itsenäinen kehitys, ja pienenä kannustimena epämuodollinen kilpailu Ruotsin kanssa. Kumpi toimisi paremmin: laaja yhteistyö mittavalla rahoituksella ja perinteisillä relaatiotietokannoilla vai ketterä kehitys pienillä resursseilla (vajaan yhden henkilön työpanos) käyttäen joustavampaa tekniikkaa?
Poikkeavia ratkaisuja ja uusi työnkuva
Luomuksen uusi järjestelmä nimettiin Kotkaksi. Samaan aikaan Luomuksessa oli tarve tallettaa monenlaista muutakin lajitietoa, kuten taksonomiaa (eli eliöiden nimiä ja sukulaisuussuhteita) ja havaintotietoja. Pitääksemme järjestelmän yksinkertaisena ja joustavana, emme päätyneet käyttämään relaatiotietokantaa, vaan ontologiatietokantaa johon tiedot tallennettaisiin näytteisiin liittyvänä ominaisuus-arvopareina. Tämä olisi nopeampi rakentaa ja joustavampi käyttää kuin esim. Specifyn käyttämä relaatiomalli (jossa on yli 160 taulua ja tuhansia kenttiä), mutta ajatus herätti kummastusta perinteisiin tietojärjestelmiin tottuneissa.
Muutenkin Kotkan kehityksen pohjaksi otettiin perinteisestä poikkeavia ja kehitystä yksinkertaistavia ratkaisuja. Kotkassa ei olisi monimutkaista tietojen hyväksymis- ja käyttöoikeushallintaa. Valtaosa tiedoista tallennettaosiin vapaatekstinä, mikä myös sopisi hyvin historialliselle datalle ja nopeuttaisi tallentamista. Virheisiin varauduttaisiin säilyttämällä koko muokkaushistoria (Wikipedian tyyliin).
Kehityksen ytimenä olisi ketteryys Scrum-tyyliin: järjestelmää kehitetään pala kerrallaan laajentaen muutaman viikon sykleissä. Mukaan otettaisiin uusia kokoelmia yksi kerrallaan. Ongelmia ratkottaisiin sitten kun ne eteen tulevat. Kehitys käynnistyi syksyllä 2011. Hankkeen tuloksena oma työni muuttui webmasterista tietojärjestelmän vastuukehittäjäksi. Olin käytännössä auttanut luomaan itselleni uuden työnkuvan.
Ketterää luovintaa – Kotkan lentoharjoitukset
Alku ei sujunut ongelmitta. Ontologiatietokantaa ei saatu käyttökuntoon. Viivytyksen jatkuessa päätin ratkaista ongelman siirtymällä käyttämään yksinkertaisempaa MongoDB-dokumenttitietokantaa (Lean startup -sanastolla technology pivot). Tämän jälkeen pääsin tekemään käyttöliittymää, jonka jälkeen sain ensimmäisen version Kotkasta koekäytettäväksi parissa viikossa.
Seuraavat kaksi vuotta Kotkaa kehitettiin hiljalleen muiden töiden ohella, uusia versioita säännöllisesti julkaisten ja kokemuksia keräten (iteroimalla!) Hyntikka oli edelleen käytössä. Vietettyäni vuoden koti-isänä palasin Kotkan pariin. Nyt kehitys lähti vauhdilla eteenpäin, kun kehitystyötä tekemään oli palkattu päätoiminen ohjelmoija ja ryhdyin itse ohjaamaan kehitystä puolipäiväisesti (product ownerina; jälleen uusi työnkuva!). Vuoden 2014 lopussa Kotkassa oli 52.000 näytettä Luomuksesta ja Kokkolan luonnontieteellisestä museosta.
Laajentuminen kansalliseksi
Vuonna 2014 Kotka saavutti erään käyttäjän sanoin “aikuisuuden”: se toimi hyvin kokoelmien hallinnassa ja käyttöönotto oli riittävän helppoa. Siirryin lähes kokopäiväiseksi product owneriksi ja datan siirtäjäksi. Työpanosta siirrettiin uusien kokoelmien tuomiseen mukaan sekä Kotkan laajentamiseen Luomuksen kasvitieteellisen puutarhan käyttöön. Uusia kokoelmia oli periaatteessa helppo ottaa mukaan Kotkan joustavuuden ansiosta, mutta hidasteena oli vanhojen, epäyhtenäisten aineistojen yhtenäistäminen ja korjailu. Vuoden aikana Kotkaan kuitenkin siirrettiin useita aineistoja mm. Hyntikasta ja Digitariumista. Näytemäärä kolminkertaistui 150.000 näytteeseen ja lainojakin ryhdyttiin kirjaamaan järjestelmään (paperikansioiden sijasta).
2015 käynnistyi hanke Suomen Lajitietokeskuksen, rakentamiseksi. Lajitietokeskuksen tavoitteena on tuoda hajallaan olevaa lajitietoa viranomaisten ja suuren yleisön käyttöön yhden luukun periaatteella ja avoimena datana. Kotka solahti luontevasti Lajitietokeskuksen osaksi ja muuttui samalla kansalliseksi tietopalveluksi. Käyttöönottoa ryhdyttiin edistämään Turun, Kuopion, Oulun, Pohjanmaan, Jyväskylän ja Satakunnan museoiden kanssa. Marraskuussa 2015 näytteitä oli tietokannassa jo yli 430.000 neljästä eri museosta. Parin päivän kokeiluprojektista oli kasvanut kansallinen tietojärjestelmä! (Vertailun vuoksi: Kansallismuseon tietokannassa oli 221.000 objektia vuonna 2015)
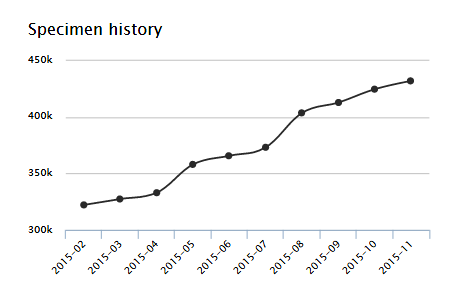
Näytemäärän kehitys helmi-marraskuussa 2015.
Tähän asti kehitystä ja käyttöönottoa oli tehty pääasiassa kahden henkilön voimin, marraskuussa mukaan saatiin kolmas auttamaan aineistojen siirrossa. Vastaanotto on ollut innostunutta ja tyytyväistä – eräänkin museolaisen mukaan on “ihanaa kun pääsemme käyttämään Kotkaa!”. Kehitys on ollut sujuvaa paljolti koska Luomukseen on muodostunut oma osaava ICT-tiimi, jolla on mahdollisuus erikoistua luonnontieteiden tarpeisiin ja tehdä päätöksiä itsenäisesti. On paljon helpompaa tehdä yhteistyötä kun kaikki työskentelvät samassa rakennuksessa käyttäjien kanssa, kuin jos kehitystyö olisi ulkoistettu.
Maaottelun ensimmäisen erän voittaja on…
Samaan aikaan ruotsalaisten vetämä DINA-hanke on käynnistynyt kansainvälisenä projektina, jossa on mukana organisaatioita kuudesta maasta. Hankkeessa on kirjoitettu suunnitelmia, sekä tehty lainanhallintatyökalu ja muutama muu osamoduuli. Varsinaisten kokoelmienhallintavälineen (DINA-Web) julkaisu on suunniteltu vuodelle 2016 – kokoelmien hallinnassa käytetään edelleen Specify-sovellusta välivaiheen työkaluna. Ei kovin ketterää. Tältä kannalta Luomuksen päätös keskittyä omaan kehityksen oli onnistunut.
Tulevaisuus
Tiedon määrän kannalta Kotkan käyttöönotto on vasta alussa. Erilaisia kokoelmatietokantoja ja taulukkoja on Suomessa edelleen kymmeniä, ja digitoimattomia näytteitä parikymmentä miljoonaa. Muitakin haasteita on vielä edessä: tietojärjestelmäkehityksen suurimmat kivikot eivät usein ole teknisiä, vaan liittyvät viestintään, ymmärtämiseen ja toimintatapojen muutoksiin. Miten voitaisin saavuttaa yhteisymmärrys oleellisimmista tavoitteista ja keskittyä niihin, sen sijaan että vain muutettaisiin vanhoja ja epäyhtenäisiä toimintatapoja sähköisiksi? Tässä riittää ratkottavaa vielä vuoksiksi, mutta lähtökodat tälle ovat nyt hyvät.
Lisää aiheesta
- Ajatuksia jumiutuneen tietojärjestelmäkehityksen ketteröittämisestä
- Kotkan taustatietoja ja käyttöohjeita
- Lajitietokeskuksen hakupalvelu (beta), jonka kautta Kotkan tiedot ovat haettavissa
- Uutisia Lajitietokeskuksen palveluista, ml. Kotkasta
- Esimerkki Kotkaan tallennetusta näytteestä: http://id.luomus.fi/GAC.11651